Long term software maintenance means sometimes features disappear

Why we sometimes drop features?
It is quite rare, but sometimes things available in one version of eLabFTW are no longer available in the next version. There could be several reasons for this:
- the feature is no longer open source: this is what happened with the image editing tools of the text editor
- the feature depends on a library or service that is no longer active/maintained
- the feature has been superseded by a superior implementation
What I wish to discuss in this post is the last point: redundancy and its associated maintenance cost. When something is no longer relevant, it’s important to get rid of it or the software becomes an unmaintainable mess!
Technical debt
All software is technical debt. Every single new line written immediately turns into something that needs to be maintained over the years. Even comments can have a maintenance cost!
So it is important to have as little code as possible to achieve the same results. Expressive code is important, but another aspect is about reducing overall complexity. This is achieved through a clean architecture, which avoids code duplication, but also making choices about the direction of the project and the things that should no longer be there.
Complexity
Over the years, an application will accumulate many functionalities, which will need to be represented in the User Interface (UI). This means more menus, buttons, and text displayed, which can ultimately result in the software becoming complicated to navigate, and users getting frustrated because they are lost in the plethora of available actions and settings.
This is not necessarily a bad thing, it means the application is growing, and these features are generally asked by the users. A good UI can help a lot with the complexity, too.
Sunk cost fallacy
But what is important is to have a vision. This is what is necessary to decide when to drop a feature. Let’s take a concrete example.
In the beginning, eLabFTW listed entries on one column. On moderately wide screen, we could see a large gap in the center, with no content:
So the idea to use all this “wasted” space was to switch to a 3-column layout, which resulted in this kind of monstrosity:
And a few issues where opened to switch back to the old layout.

To make it short:
- we added an option to use the original layout
- later we made the 3 columns non-default
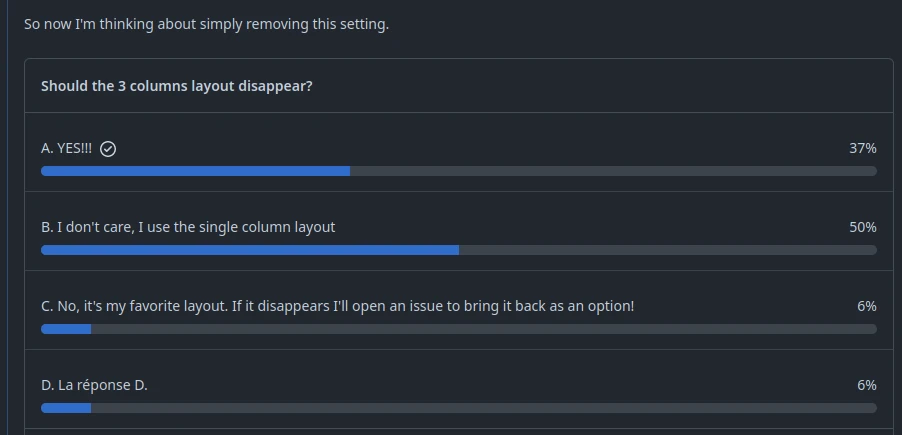
- we polled the community about dropping the three columns layout:
Because having to maintain this layout meant making sure changes work with both layouts (+ the table layout), and there was a clear cost associated with this, because it’s also a user option, and it needs text to be translated, etc…
So even if we invested time and effort into making it work, it was time to let it go (let it goooooo 🎵).
It is important to recognize mistakes, and it is dangerous for a software project to continue the maintenance on something ill-designed if the only reason is to avoid the waste of person-hours invested in its creation.
Or you end up with a mess on your hands. Something like the Microsoft Windows operating system, where you can actually see this accumulation by the multiple UI systems present on a single version. See this blog post about UI inconsistencies in Windows 10.
Dropping APIv1
Another example is the drop of APIv1. When the public REST API was added, it was done without really thinking too much about it, and at the time the internal software architecture was quite different. This ended up with a poorly designed API.
Once APIv2 started to stabilize, it was time to remove the APIv1 code. In an ideal world we would be able to maintain v1 and v2 at the same time, but v1 started really weighting on the maintenance, so the decision was taken to simply remove it from the application, after a period of deprecation so users have the time to move their script to APIv2.
Again, dropping old features allows for better focus on current ones, which benefits users in the end, because the dev team does not spend time fixing bugs related to antique code paths.
But why drop zip import, though?
More recently (with version 5.1), the support for .zip import has been dropped.
At first, .zip import was created with a simple idea: drop a JSON file in there that will contain all the information needed. And it worked. Many subtle bugs appeared over time, such as the need to truncate long titles and other niceties.
Then came .eln import, which is a somewhat similar approach with a main JSON file describing the content. Except it is an interoperable standard, whereas the .elabftw.json file present in eLabFTW ZIP archives would only work in eLabFTW.
That’s when the period of fixing stuff for ZIP meant doing roughly the same for ELN.
With 5.1 the ELN import and export was vastly improved, and there are many challenges when you wish to import something in eLabFTW properly and robustly. So all this work would have needed to be duplicated for ZIP, too. Which in a perfect world wouldn’t be an issue because the code is so clean that this is easy, but in the real world, it quickly becomes a burden.
And because the ZIP import is basically the same as ELN, it was decided to drop the ZIP import code (not export, that stays). This decision will save a lot of maintenance over time, as we can now focus on only two file formats and make them super easy to import.
Time to conclude, no?
Yes, let’s conclude: too many features = good but also bad. No refactor and no feature drop = bad. Vision good.
Here is a blog post roughly concluding the same: https://www.gkogan.co/removing-stuff/.